Wichtig vorab
Achte darauf, dass Deine Scanvorlagen und die Auflage Deines Scanners sauber sind.
Staub oder Krümel (auch von Tabak) solltest Du deshalb vorher mit einem weichen und trockenen Tuch entfernen!
Und auch den Schutzumschlag brauchst Du beim Scannen nicht…
Die ersten Schritte
Wenn Du schon einen Scanner besitzt, wirst Du vermutlich im Grundsatz auch wissen, wie man ihn bedient. Und einiges hatte ich dazu ja auch schon in den vorhergehenden Kapiteln dieser Anleitung geschrieben.
Dennoch möchte ich jetzt anhand der (manchmal etwas fuddeligen, weil unübersichtlichen) Software meines alten Flachbettscanners nochmal näher auf ein paar Punkte eingehen, die später der Texterkennung (und auch Dir!) die Arbeit sicher erleichtern werden, wenn es um das Erstellen von Ebooks aus gedruckten Texten geht.
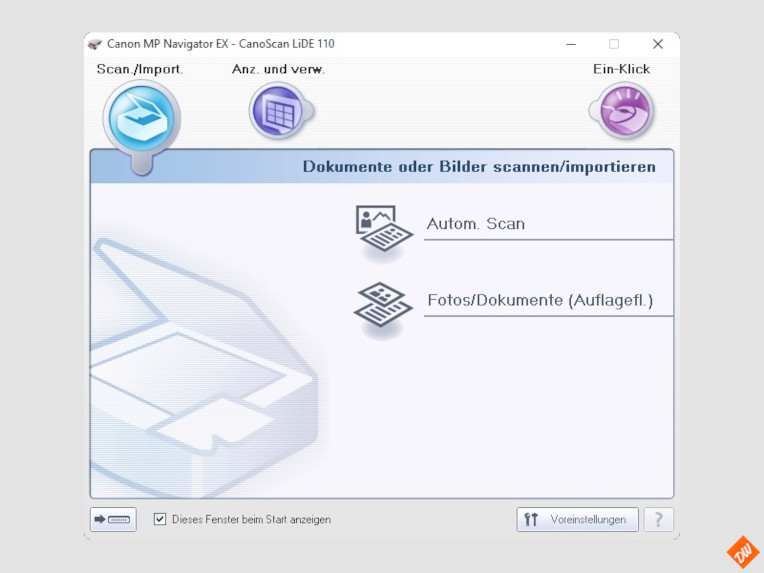
Wobei natürlich jedes Scannermenue anders aussieht und Du bei der Software Deines Scanners vermutlich manche Einstellungen an anderer Stelle findest.
Aber das macht auch nichts, denn prinzipiell sollten eigentlich alle Hersteller in ihrer Software alle Einstellungsmöglichkeiten bieten.
Und zur Not hilft ja auch das Handbuch weiter.
Grundeinstellung .
Wichtig ist auf jeden Fall, von Anfang an den Modus zu wählen, der sich ja auch nach der weiter geplanten Verwendung der Scans richtet.
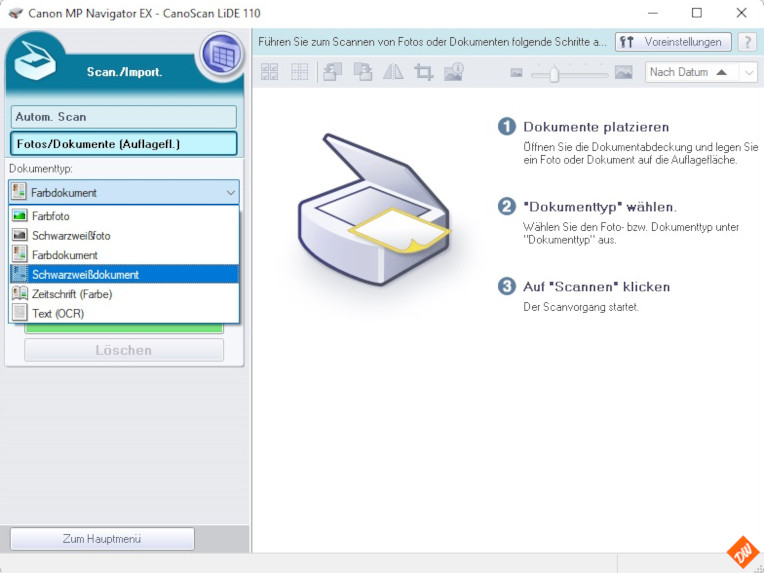
Möchte ich die Texte anschliessend weiter mit meiner Texterkennung bearbeiten, also auf jeden Fall „Schwarzweissdokument“ – möchte ich sie lediglich als „nur-PDF“ auf dem Tablett oder Rechner nutzen ist „Zeitschrift“ oder „Farbfoto“ die bessere Wahl.
Den auch an dieser Stelle schon angebotenen OCR-Modus können wir aber erst mal noch vernachlässigen, weil der für unser Zwecke kaum taugt und es zum erstellen eines Stichwortverzeichnisses für durchsuchbare „nur-PDF“ im späteren Verlauf noch eine weitere Variante gibt
Auflösung
Der zweite wichtige Punkt ist die Auswahl der richtigen DPI-Wertes, der für die Texterkennung am Besten 300 DPI betragen sollte, während für die Erstellung von „nur-PDF“-Formaten auch 150 DPI meist reichen
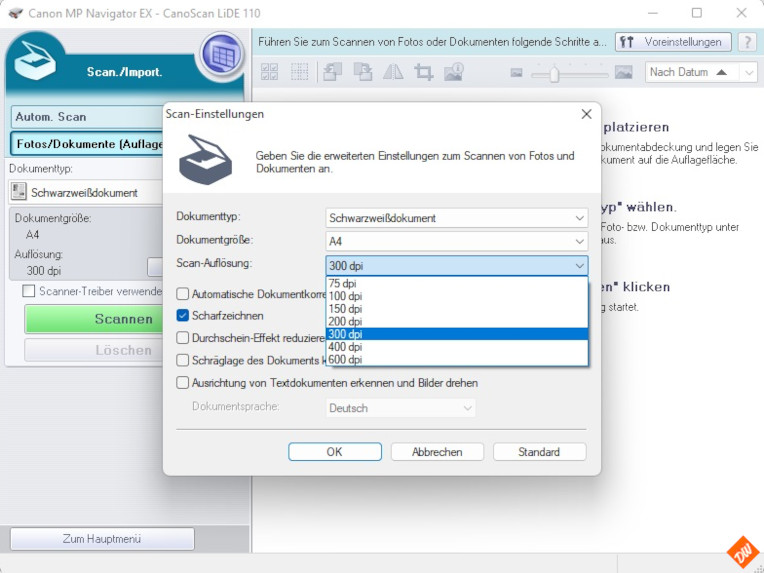
Dabei sind die 300 DPI ein Kompromisswert, zwischen Qualität, Dateigrösse und Zeitaufwand. Höhere Auflösung könnten zwar ggf. die Ergebnisse der Texterkennung verbessern,
( erinnerest Du dich an die zu eng stehenden Worte, mit denen die Texterkennung bei allen meine Scannern Probleme hatte?)
bedingen aber auch, dass manche Scanner fühlbar langsamer arbeiten, der Speicherplatzbedarf für die Scan-Ergebnisse (egal ob JPG oder PDF) enorm steigt und die Texterkennung für ihre Arbeit noch mehr Zeit braucht – meist ohne das daraus grosse Gewinne für die nachfolgenden Arbeitsschritte entstehen würden.
Mehrfach-Scans
Ich hatte ja schon erwähnt, das es aus meiner Erfahrung heraus am günstigsten ist, beim Scannen die Vorlage gleich in gut handhabbare Häppchen aufzuteilen.
20 bis maximal 40 Seiten sind dafür ein brauchbarer Wert, mit dem sowohl die Texterkennung als auch ich selbst bei der anschliessenden Textverarbeitung gut klar kommen. Wobei ich tendenziell inzwischen meist bei Päckchen von 30 Seiten lande, je nachdem, wieviel Inhalt die einzelnen Seiten der Vorlage enthalten.
Ausnahmen davon mache ich nur, wenn ich Vorlagen habe, aus denen ein „nur-PDF“-Format entstehen soll. Dann scanne ich auch mal die ganze Vorlage am Stück oder Kapitelweise, wenn ich anchliessend ein Inhaltsverzeichnis brauche. (darauf gehe ich aber im Thema Textverarbeitung auch nochmal näher ein)
Netterweise bietet mir meine Scannersoftware für dieses Vorgehen auch gleich eine passende Möglichkeit:
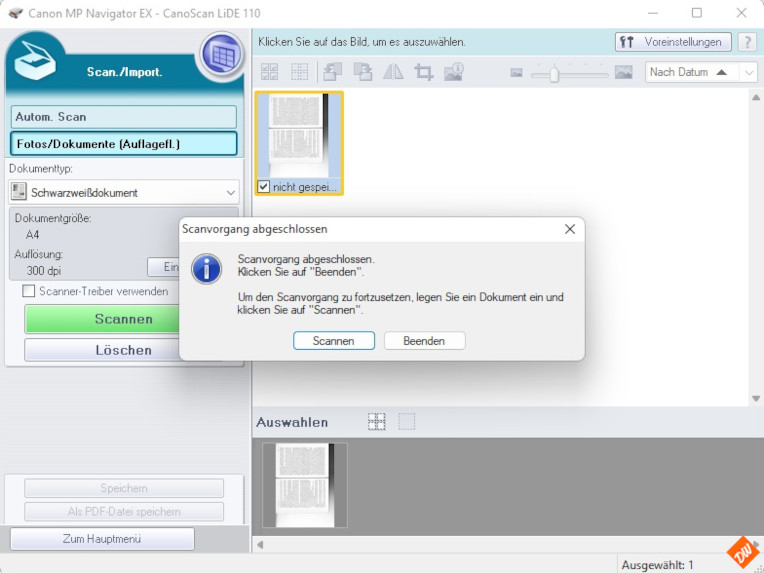
Und ich vermute, diese Möglichkeit wir es auch bei anderen Herstellern geben – wenn auch womöglich an anderer Stelle innerhalb der Scannersteuerung.
Erste Bildbearbeitung
Während die Software meiner beiden anderen Scanner diesen Schritt gleich automatisch ausführt, muss ich beim Flachbettscanner vor dem Speichern noch selbst ein wenig Hand anlegen:
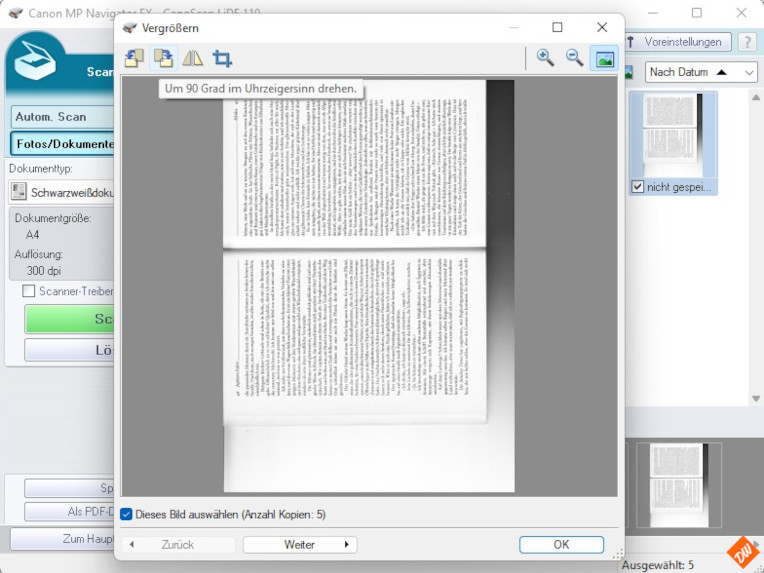
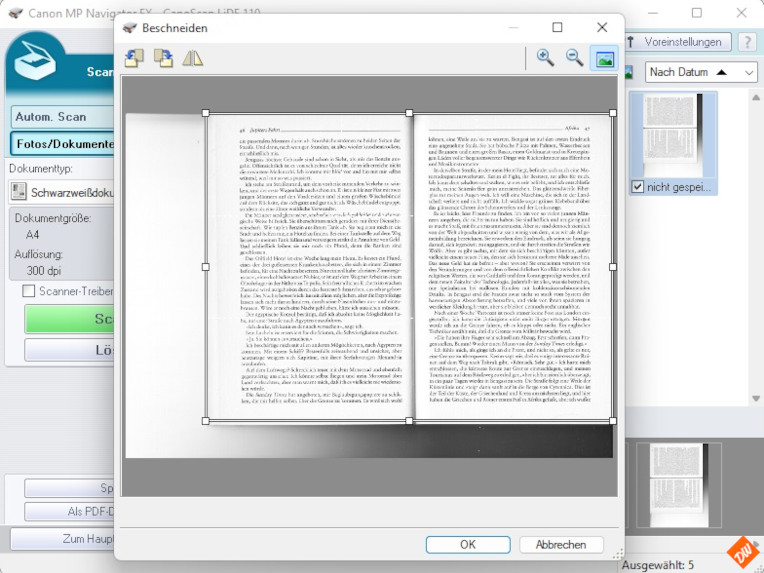
Ausrichten, weil Flachbettscanner prinzip-bedingt immer im Hochformat scannen und das bei einer Doppelseite natürlich nicht passt – und Zuschneiden auf den Inhaltsbereich als Vorbereitung für die Texterkennung – aber auch (bei „nur -PDF“) um die optische Anmutung der Scans ein wenig zu verbessern und gleichzeitig den Speicherplatzbedarf ein wenig zu verringern.
Was nicht im Bild enthalten ist, frisst da auch keinen Platz.
Speichern als PDF
Kommt als letzter Schritt das grosse Finale der Scan-Aktion: Der Export in eine PDF-Datei:
und damit unter „Einstellungen“ auch die Möglichkeit, PDF-Dateien durchsuchbar zu machen, falls man das braucht – etwa für Hand-oder Fachbücher:
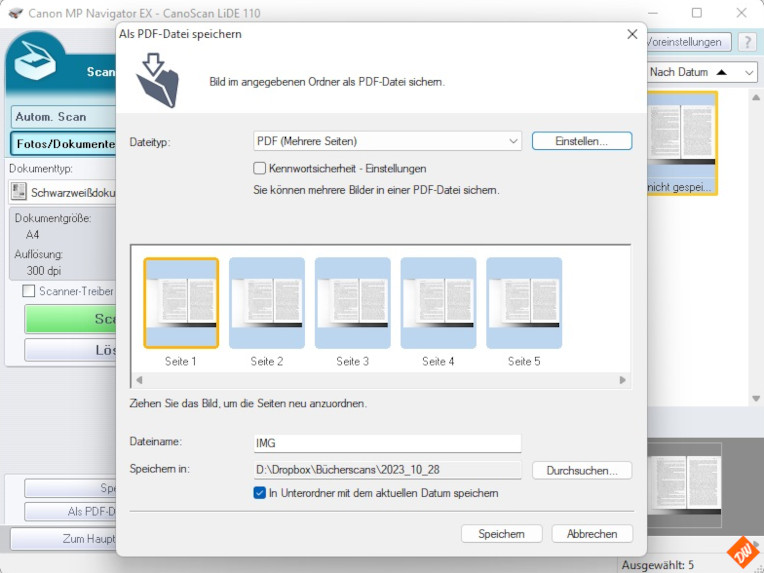
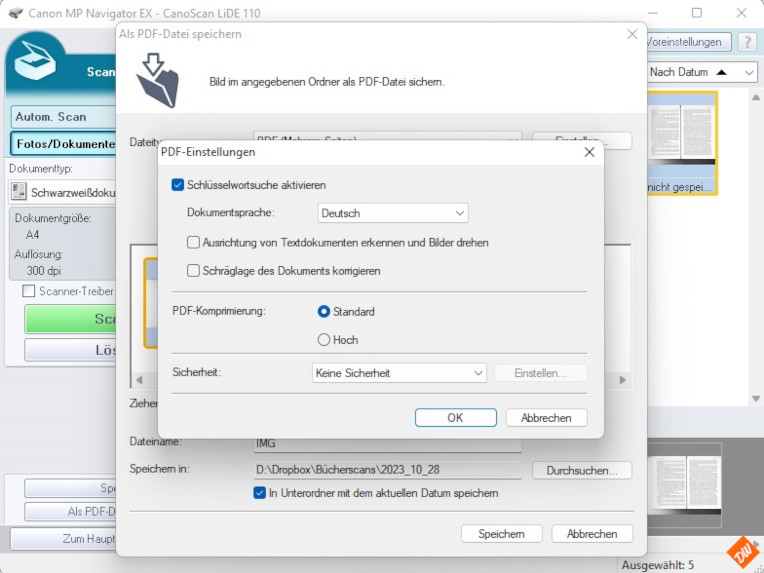
Doch das macht für unsere weitere Bearbeitung in der Texterkennung wenig Sinn und könnte sogar hinderlich werden, weil wir damit natürlich auch die PDF-Dateien noch weiter aufblähen.
Deswegen sollte man diese Option auf jeden Fall ausschalten, wenn man sie nicht braucht.
Doch das macht für unsere weitere Bearbeitung in der Texterkennung wenig Sinn und könnte sogar hinderlich werden, weil wir damit natürlich auch die PDF-Dateien noch weiter aufblähen.Deswegen sollte man diese Option auf jeden Fall ausschalten, wenn man sie nicht braucht.
Und nach dem Speichern uns kurzer Wartezeit:
Das Ergebnis
Damit kann man doch arbeiten:

Gute Scans minimieren nun mal die Fehlerquote bei der Texterkennung und damit auch die manuelle Nacharbeit bei der Textverarbeitung. Deshalb lohnt es sich auf jeden Fall, sich die Mühe sorgfältigen Arbeitens auch schon beim Scannen zu machen und dafür die notwendige Zeit zu investieren…
Zum Scannen von Bildern
Natürlich wird es auch vorkommen, dass Du Bilder für Dein Ebook brauchst. Zumindest ein Titelbild gibt es ja immer. Deshalb gibt es bezogen darauf auch Besonderheiten beim Scannen, die ich nicht unerwähnt lassen will:
Bildern für Dein Ebook / oder Deine selbst nachbearbeitete PDF solltest Du in einem Zweiten Durchgang nochmal separat in Farbe oder zumindest in Graustufen mit ebenfalls mindestens 300 DPI einscannen, um eine brauchbare Vorstufe für die noch folgende Bildbearbeitung zu haben.
Die Scans im Textmodus reichen dafür auf keinen Fall aus, weil dabei einfach zu viele Details verloren gehen.
Für „nur-PDF“ reicht üblicherweise der farbige Scan mit 150 DPI zur Darstellung auf Tablets und am Rechner aus, in dem Du deren Vorlagen (und damit auch die Bilder) ohnehin einscannst. Mehr lohnt (mit Rücksicht auf Dateigrössen und Ladezeiten) allenfalls für hochwertige Bildbände, die Du auf diese Art konservieren willst.
Und noch eine kleine Nachbemerkung
Für mich ist das Scannen der Vorlagen immer der lästigste Teil des gesamten Workflows, obwohl ich inzwischen in der komfortablen Lage bin, mir dafür jeweils das beste Gerät aussuchen zu können. Dennoch habe ich mir gelegentlich auch schon überlegt, bei umfangreicheren Vorlagen professionelle Hilfe durch Copyshops zu suchen, die das gelegentlich auch anbieten und dank ihre Profigeräte auch gute Qualität abliefern.
Auch das könnte also eine Variante für Dich sein, wenn Du den hohen Preis für solche Dienste nicht scheust und Dein Geld nicht lieber in einen guten Scanner investieren möchtest.
Soviel dazu – und nun weiter zur Texterkennung
Fragen, Anmerkungen und
Kommentare unter dem Blogbeitrag
Weiter zu: Workflow (III): Texterkennung ->